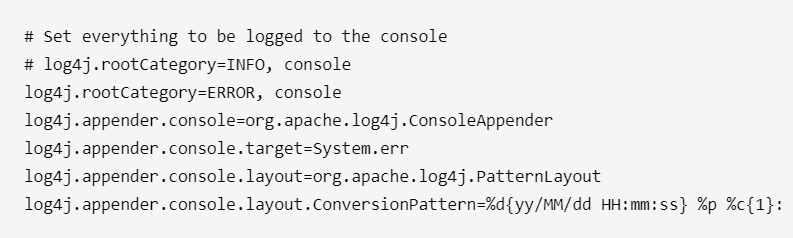
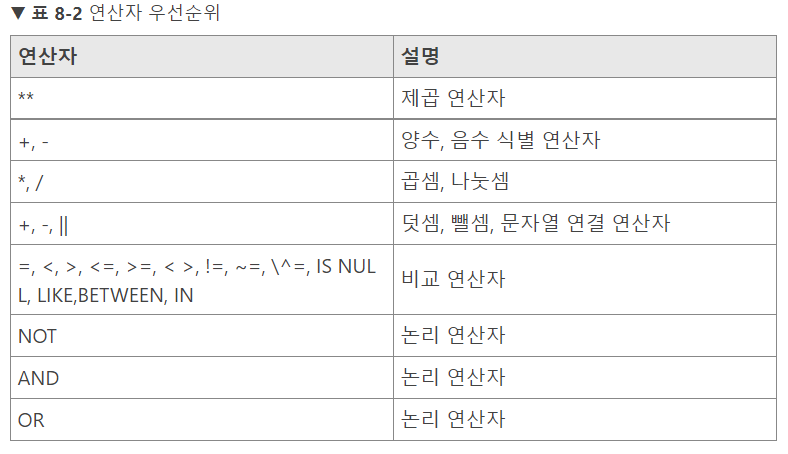
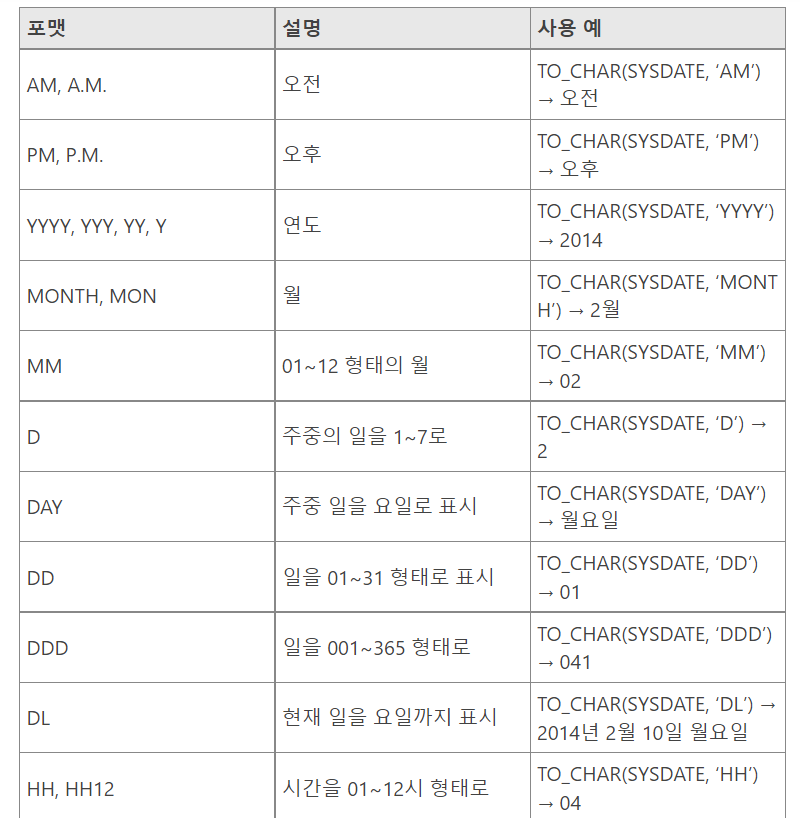
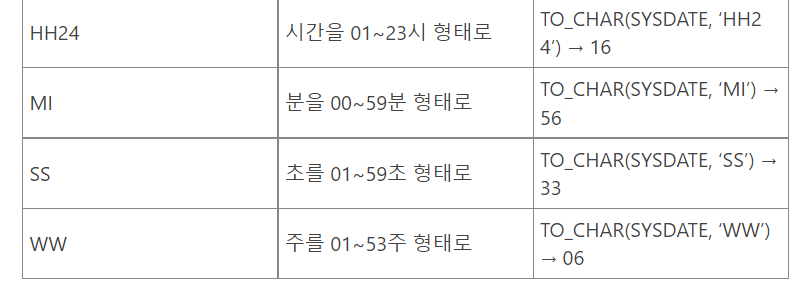
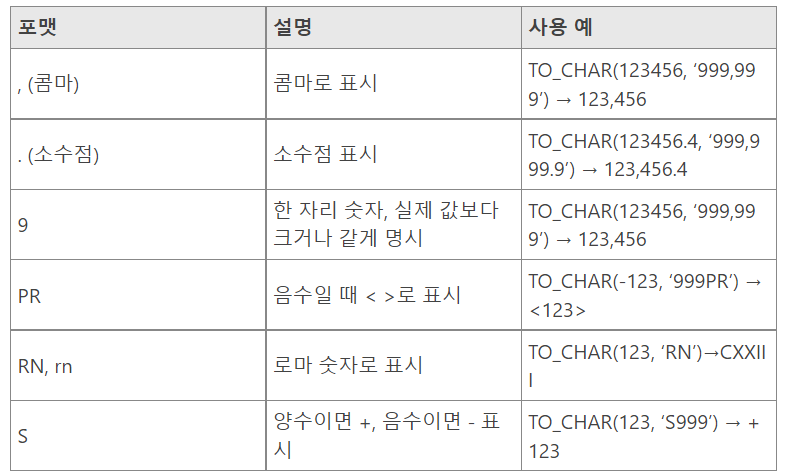
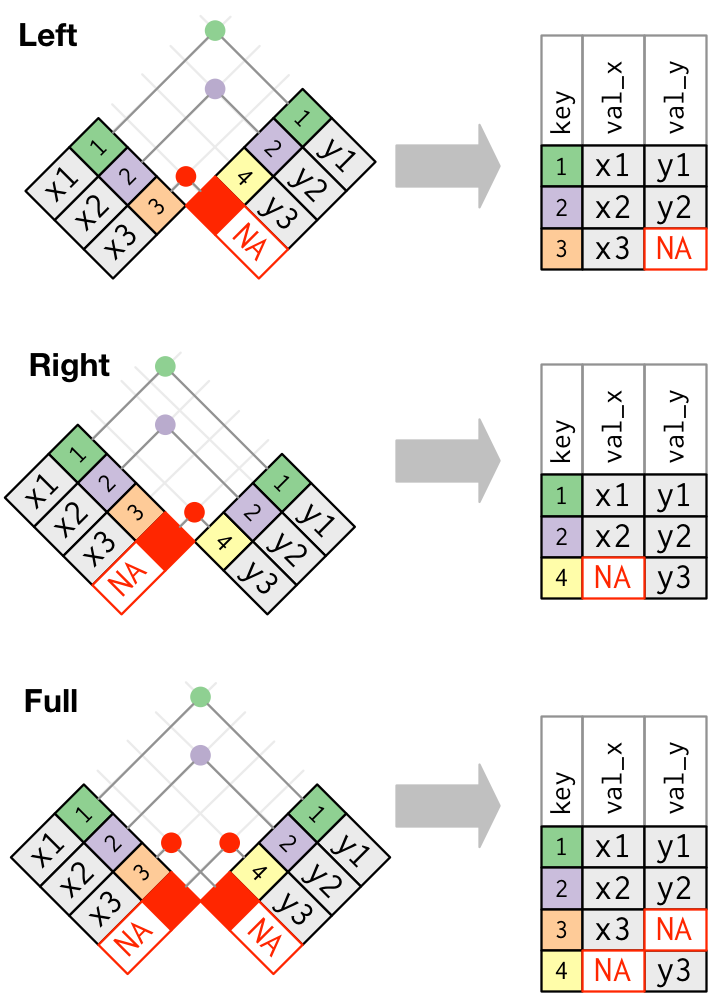
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| # (1) + (2)
SELECT
emp.years
, emp.employee_id
, emp2.emp_name
, emp.amount_sold
FROM
(SELECT
SUBSTR(a.sales_month, 1, 4) as years
, a.employee_id
, SUM(a.amount_sold) AS amount_sold
FROM
sales a
, customers b
, countries c
WHERE a.cust_id = b.cust_id
AND b.country_id = c.country_id
AND c.country_name = 'Italy'
GROUP BY SUBSTR(a.sales_month, 1, 4), a.employee_id) emp
, (SELECT
years
, MAX(amount_sold) AS max_sold
, MIN(amount_sold) AS min_sold
FROM (SELECT
SUBSTR(a.sales_month, 1, 4) as years
, a.employee_id
, SUM(a.amount_sold) AS amount_sold
FROM
sales a
, customers b
, countries c
WHERE a.cust_id = b.cust_id
AND b.country_id = c.country_id
AND c.country_name = 'Italy'
GROUP BY SUBSTR(a.sales_month, 1, 4), a.employee_id) K
GROUP BY years) sale
, employees emp2
WHERE emp.years = sale.years
AND emp.amount_sold = sale.max_sold
AND emp.employee_id = emp2.employee_id
ORDER BY years;
|