SQL basic
SQL
SELECT문
기본 구조
- SELECT * 혹은 컬럼 —> 무엇을 가져올껀지
- FROM 테이블 또는 VIEW —> 어디서 가져올껀지
- WHERE 조건 —> 어떻게 가져올껀지
- ORDER BY 컬럼;
- 예시 (교재 3장)
1
2
3
4
5
6SELECT
employess_id, emp_name, salary, job_id
FROM
employees
WHERE salary > 5000;
ORDER BY employee_id;AND와 OR 조건
- WHERE 조건에 AND나 OR의 옵션을 줄 수 있다
- 예시
1
2
3
4
5
6
7SELECT
employess_id, emp_name, salary, job_id
FROM
employees
WHERE salary > 5000;
AND job_id ='IT_PROG'
ORDER BY employee_id;
MERGE 문
- 조건과 비교하여 값이 있으면 UPDATE / 없으면 INSERT를 진행해주는 구문
- 코드 실습
1
2
3
4
5
6
7
8# 테이블 만들기
INSERT INTO ex3_3 (employee_id)
SELECT
e.employee_id
FROM employees e, sales s
WHERE e.employee_id = s.employee_id
AND s.SALES_MONTH BETWEEN '200010' AND '200012'
GROUP BY e.employee_id;- (1) 관리자 사번(manager_id)이 146번인 사원을 찾는다.
(2) ex3_3 테이블에 있는 사원의 사번과 일치하면 보너스 금액에 자신의 급여의 1%를 보너스로 갱신
(3) ex3_3 테이블에 있는 사원의 사번과 일치하지 않으면 (1)의 결과의 사원을 신규로 입력(이 때 보너스 금액은 급여의 0.1%
(4) 이 때 급여가 8000미만인 사원만 처리해보자.
1
2
3
4
5
6SELECT employee_id, manager_id, salary, salary * 0.01
FROM employees
WHERE employee_id IN (SELECT employee_id FROM ex3_3);
# ex3_3 테이블에 있는 사원의 사번, 관리자 사번, 급여, 급여*0.01을 조회한 것
# ex3_3 테이블에서 관리자 사번 146인 사원의 보너스 금액을 급여*0.01로 갱신1
2
3
4
5
6
7SELECT employee_id, manager_id, salary, salary * 0.001
FROM employees
WHERE employee_id NOT IN (SELECT employee_id FROM ex3_3)
AND manager_id = 146;
# 사원 테이블에서 관리자 사번이 146인 것 중 ex3_3 테이블에 없는 사원의 사번, 관리자 사번 급여, 급여*0.001을 조회한것
비교조건식
ANY
- OR 의 역할
- 급여가 2000 이거나 3000, 4000인 사원을 추출
1
2
3
4
5
6SELECT
employee_id
, salary
FROM employees
WHERE salary = ANY(2000,3000,4000)
ORDER BY employee_id;ALL
- AND 의 역할
- 모든 조건을 동시에 만족해야 함
1
2
3
4
5
6SELECT
employee_id
, salary
FROM employees
WHERE salary = ALL(2000,3000,4000)
ORDER BY employee_id;SOME
- ANY 와 같은 동작을 함
논리 조건식
- AND
- OR
- NOT
- 조건식이 거짓일 때의 결과를 반환
NULL 조건식
- 특정 값이 NULL 인지 여부를 확인함
- 등호 연산자를 사용하지 않는다
- “salary IS NULL” 혹은 “salary IS NOT NULL”
BETWEEN AND 조건식
- 범위에 해당되는 값을 찾을 때 사용
- ‘≥’ 와 ‘≤’ 논리 연산자로 변환이 가능
IN 조건식
- 조건에 포함된 값을 반환
- ‘=ANY’ 형태로 바꿔 쓸 수 있음
- 비교나 등호 연산자 (‘=’) 를 쓰지 않음
1 | SELECT |
- NOT IN
- 조건에 포함되지 않은 모든 값을 반환
- 마찬가지로 비교나 등호 연산자를 사용하지 않음
- ‘<>ALL’ 이랑 같은 동작
EXISTS 조건식
- IN과 비슷한 동작
- 서브 쿼리에만 사용 가능
LIKE 조건식
문자열의 패턴을 검색할 때 사용하는 조건식
% 위치에 따라 앞의 문자열에 대한 조건인지 뒤에 문자열에 대한 조건인지가 달라짐
- 사원 테이블에 사원 이름이 ‘A’로 시작되는 사원 조회
1
2
3
4SELECT emp_name
FROM employees
WHERE emp_name LIKE 'A%'
ORDER BY emp_name;- ‘a’로 끝나는 사원 조회
1
2
3
4SELECT emp_name
FROM employees
WHERE emp_name LIKE '%a'
ORDER BY emp_name;‘_’ (언더스코어)는 나머지 글자 전체가 아닌 한 글자만 비교
- 문자열 세번째가 ‘c’인 사원 조회
1
2
3
4SELECT emp_name
FROM employees
WHERE emp_name LIKE '__c%'
ORDER BY emp_name;
SQL함수
숫자함수
ABS
- 절댓값 반환 함수
ROUND
- 소수점 기준 n번째에서 반올림
- 소수점 1자리에서 반올림
1
2
3
4SELECT
ROUND(10.154,1)
, ROUND(-10.154,1)
FROM DUAL;- 음수를 지정하면 일의 자리부터 시작하여 반올림 (-1을 지정하면 일의자리, -2를 지정하면 십의 자리에서)
1
2
3
4
5SELECT
ROUND(0, 3)
, ROUND(115.155, -1)
, ROUND(115.155, -2)
FROM DUAL;TRUNC
- 절삭 함수
- 반올림이 아니라 n번째에서 절삭한다
1
2
3
4
5
6SELECT
TRUNC(115.155)
,TRUNC(115.155,1)
,TRUNC(115.155,2)
,TRUNC(115.155,-2)
FROM DUAL;POWER(n2, n1) & SQRT(n)
- 제곱과 제곱근 함수
- POWER(3,2) = 9 / SQRT(9)=3
MOD, REMAINDER
- MOD는 n2를 n1으로 나눈 나머지 값을 반환
- MOD(19,4) = 3
- REMAINDER 또한 n2를 n1으로 나눈 나머지 값을 반환
- 내부적으로 계산 방법이 MOD와 약간 다름
- REMAINDER(19, 4) = -1
EXP(n), LN, LOG
- EXP(n)은 지수함수로 n제곱 값을 반환
- LN은 자연로그 함수로 밑수가 e인 로그 함수
- LOG는 n2를 밑수로 하는 n1의 로그 값을 반환
문자함수
CONCAT(char1,char2)
- ‘||’ 연산자처럼 두 문자를 합쳐줌
- CONCAT(’I Have’, ‘ A Dream’) = ‘I Have A Dream’
SUBSTR
- 문자 개수 단위로 문자열 자름
- SUBSTR(‘ABCDEFG’,1, 4) = ‘ABCD’
SUBSTRB
- 문자열의 바이트 수만큼 자름
- SUBSTRB(’ABCDEFG’,1,4) = ‘ABCD’
LTRIM(char,set), RTRIM(char,set)
- LTRIM은 char 문자열에서 set으로 지정된 문자열을 왼쪽 끝에서 제거한 후 나머지 문자열 반환
- RTRIM은 반대로 오른쪽 끝에서 제거한 뒤 나머지 문자열 반환
- set은 생략 가능
- LTRIM(‘가나다라’, ‘가’) = 나다라
- RTRIM(’가나다라’,’라’) = 가나다
- 보통 양 끝에 있는 공백을 제거할 때 자주 사용
LPAD, RPAD
- LPAD는 매개변수로 들어온 문자열을 n자리만큼 왼쪽부터 채워 추가된 문자열을 반환
- RPAD는 오른쪽에 해당 문자열을 채워 반환
1
2
3
4
5
6
7
8
9
10
11
12CREATE TABLE ex4_1(
phone_num VARCHAR(30)
);
INSERT INTO ex4_1 VALUES('111-1111');
INSERT INTO ex4_1 VALUES('111-2222');
INSERT INTO ex4_1 VALUES('111-33333');
SELECT * FROM ex4_1;
SELECT LPAD(phone_num,12,'(02)') FROM ex4_1; # (02)111-1111 ...
SELECT RPAD(phone_num,12,'(02)') FROM ex4_1; # 111-1111(02_ ...REPLACE(char, search_str, replace_str)
- 문자열에서 바꿀 문자열을 찾아, 바꾸려는 문자열로 대체하는 것
TRANSLATE(expr, FROM_str, to_str)
- replace와 비슷하지만 translate은 문자열 자체가 아닌 한 글잤기 매핑해 바꾼 결과를 반환
날짜함수
- SYSDATE, SYSTIMESTAMP
- 현재 일자를 알려줌 / 현재 일자와 시간을 알려줌
- ADD_MONTHS( date, integer)
- 매개변수로 들어온 날짜에 integer만큼의 월을 더한 날짜를 반환
- MONTHS_BETWEEN(date1, date2)
- 두 날짜 사이의 개월 수를 반환
- LAST_DAY(date)
- date 날짜를 기준으로 해당 월의 마지막 일자를 반환
- ROUND(date, format), TRUNC(date, format)
- ROUND는 format에 따라 반올림한 날짜를 , TRUNC는 잘라낸 날짜를 반환
- NEXT_DAT(date, char)
- date를 char에 명시한 날짜로 다음 주 주중 일자를 반환
변환함수
서로 다른 유형의 데이터 타입으로 변환해 결과를 반환하는 함수
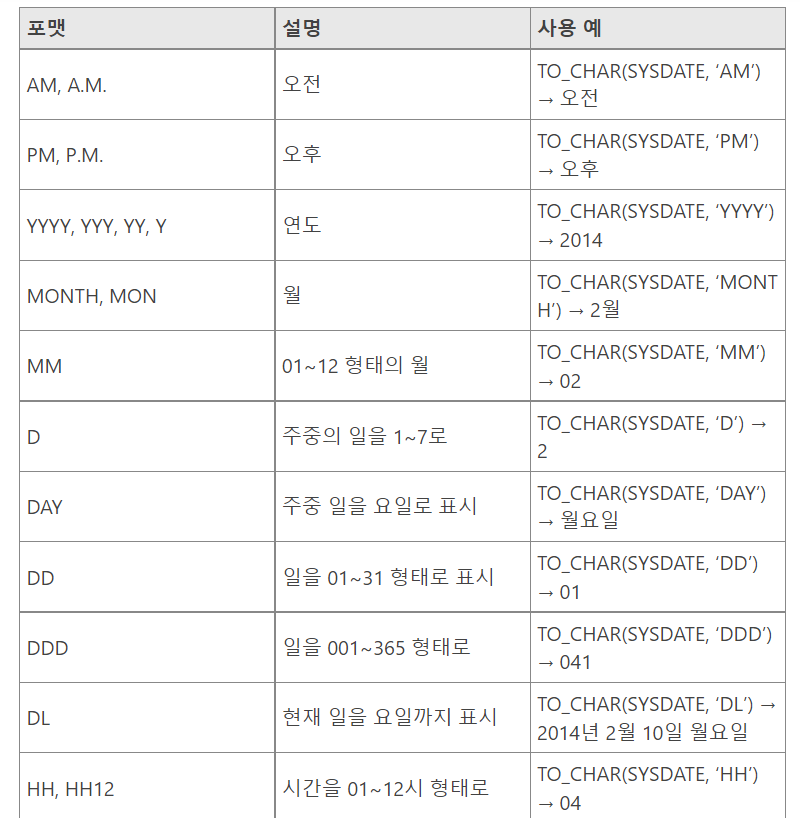
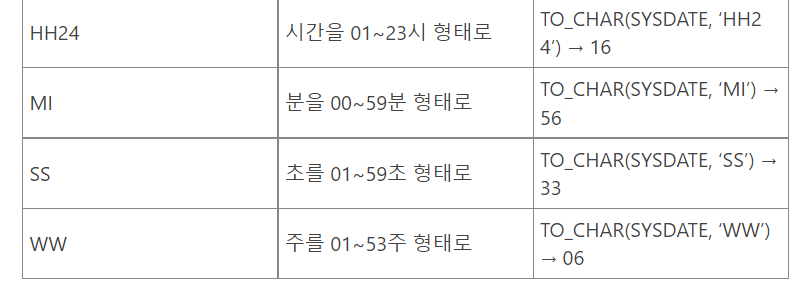
TO_CHAR(숫자 혹은 날짜, format)
- 숫자나 날짜를 문자로 변환해 주는 하무
- 날짜 변환 형식
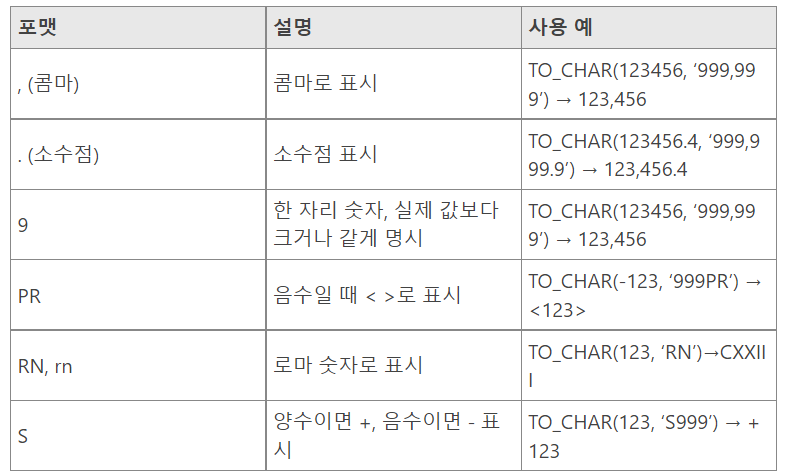
- 숫자 변환 형식
- TO_NUMBER
- 문자나 다른 유형의 숫자를 NUMBER형으로 변환하는 함수
- TO_DATE (char, format), TO_TIMESTAMP (char, format)
- 문자를 날짜형으로 변환하는 함수
- TO_DATE는 DATE형으로 TO_TIMESTAMP는 TIMESTAMP형으로 변환
NULL 관련 함수
NVL(expr1, expr2), NVL2((expr1, expr2, expr3))
- NVL 함수는 expr1이 NULL일 때 expr2를 반환한다
- NVL2 함수는 NVL을 확장한 함수로 expr1이 NULL 이 아니면 expr2를, NULL이면 expr3을 반환하는 함수이다
- 커미션이 NULL인 사원은 그냥 급여를 NULL이 아닌 사원은 급여 + (급여 * 커미션)을 조회하는 쿼리
1
2
3SELECT employee_id,
NVL2(commission_pct, salary + (salary * commission_pct),salary) AS salary2
FROM employees;COALESCE (expr1, expr2..)
- 매개변수로 들어오는 표현식에서 NULL이 아닌 첫번째 표현식을 반환하는 함수
- 급여 * 커미션 값이 NULL이면 salary를, NULL 이 아니면 급여 * 커미션을 반환하는 쿼리
1
2
3SELECT employee_id, salary, commission_pct,
COALESCE (salary * commission_pct, salary) AS salary2
FROM employees;LNNVL (조건식)
- 매개변수로 들어오는 조건식의 결과가 FALSE나 UNKNOWN이면 TRUE를, TRUE이면 FALSE를 반환한다
- 커미션이 0.2이하인 사원 조회 (null도 포함하여)
1
2
3SELECT COUNT(*)
FORM employees
WHERE LNNVL(commission_pct >= 0.2);NULLIF (expr1, expr2)
- expr1과 expr2를 비교해 같으면 NULL을 같지 않으면 expr1을 반환한다
- job_history 테이블에서 start_date와 end_date의 연도만 추출해 두 연도가 같으면 NULL을, 같지 않으면 종료 년도를 출력하는 쿼리
1
2
3
4
5SEELECT employee_id
,TO_CHAR(start_date,'YYYY')start_year
,TO_CHAR(end_date, 'YYYY') end_year
, NULLIF(TO_CHAR(end_date, 'YYYY'), TO_CHAR(start_date, 'YYYY')) nullif_year
FROM job_history;
기타 함수
- GREATEST(expr1, expr2…), LEAST(expr1, expr2…)
- GREATEST는 매개변수로 들어오는 표현식에서 가장 큰 값을, LEAST는 가장 작은 값을 반환하는 함수
- DECODE(expr, search1, result1, search2, result2, …, default)
- expr과 search1을 비교해 두 값이 같으면 result1을 , 같지 않으면 다시 search2와 비교해 값이 같으면 result2를 반환… 이런 식으로 계속 비교한 뒤 최종적으로 같은 값이 없으면 default 값을 반환
그룹 쿼리
COUNT (expr)
- 전체 로우 혹은 조건으로 걸러진 로우 수를 반환하는 집계 함수
- 대부분은 COUNT(*) 형태로 사용하는데 *에 컬럼명을 넣기도 함
- 또한 COUNT함수는 매개변수가 NULL이 아닌 건에 대해서만 로우의 수를 반환
- 앞에 DISTINCT를 붙이면 컬럼에 있는 유일한 값만 조회됨
SUM (expr)
- 전체 합계를 반환하는 함수
- COUNT와 마찬가지로 DISTINCT를 쓸 수 있음
AVG (expr)
- 매개변수의 평균값을 반환하는 함수
MIN(expr), MAX(expr)
- 각각 최솟값과 최댓값을 반환
- DISTINCT를 사용할 수는 있지만 각각 최솟값과 최댓값을 반환하므로 굳이 DISTINCT를 사용할 필요는 없음
VARIANCE(expr), STDDEV(expr)
- VARIANCE 는 분산을, STDDEV는 표준편차를 구해 반환하는 함수
GROUP BY 절과 HAVING절
- 특정 그룹으로 묶어 데이터를 집계해주는 함수
- WHERE와 ORDER BY절 사이에 위치함
- 사원테이블의 각 부서별 급여 총액 구하기
1
2
3
4SELECT department_id, SUM(salary)
FROM employees
GROUP BY department_id
ORDER BY department_id;- HAVING절은 GROUP BY 절 다음에 위치해 GROUP BY한 결과를 대상으로 다시 필터를 거는 역할
- 2013년 지역별 가계 대출 총 잔액에서 대출 잔액이 100조 이상인 건만 추출하기
1
2
3
4
5
6SELECT period, region, SUM(loan_jan_amt) totl_jan
FROM kor_loan_status
WHERE period = '201311'
GROUP BY period, region
HAVING SUM(loan_jan_amt) > 100000
ORDER BY region;ROLLUP절과 CUBE절
- 둘다 GROUP BY 절에서 사용되며 그룹별 소계를 추가로 보여주는 역할을 함
- ROLLUP은 expr로 명시한 표현식을 기준으로 집계한 결과, 즉 추가적인 집계 정보를 보여줌
- 2013년도 대출 종류별 총 잔액에 롤업 적용 →
1
2
3
4
5SELECT period, gubun, SUM(loan_jan_amt) totl_jan
FROM kor_loan_status
WHERE period LIKE '2013%'
GROUP BY period, gubun
ORDER BY ROLLUP(period, gubun);- CUBE는 rollup이 레벨별로 순차적 집계를 한 반면, 명시한 표현식 개수에 따라 가능한 모든 조합별로 집계한 결과를 반환한다
- CUBE는 2의 제곱(expr 수) 만큼 종류별로 집계 된다.
집합연산자
- UNION
- 합집한을 의미 → 데이터 집합 각각의 집합 원소를 모두 포함한 결과가 반환됨
- UNION ALL
- UNION과 비슷한데 중복된 항목도 모두 조회해주는 함수
- INTERSECT
- 교집합을 의미 → 데이터 집합에서 공통된 항목만을 추출
- MINUS
- 차집합을 의미 → 한 데이터 집합을 기준으로 다른 데이터 집합과 겹치는 항목을 제외하여 결과를 추출
조인
내부조인과 외부조인
동등조인
- WHERE절에서 등호 연산자를 사용해 2개 이상의 테이블이나 뷰를 연결한 조인
- A와 B 테이블 사이에서 공통된 값을 가진 컬럼의 행을 추출
1
2
3
4
5
6
7
8
9SELECT
a.employee_id
, a.emp_name
, a.department_id
, b.department_name
FROM
employees a
, departments b
WHERE a.department_id = b.department_id;EXISTS
- 서브 쿼리를 사용해 서브 쿼리에 존재하는 데이터만 메인 쿼리에서 추출하는 조인 방법
- B 테이블에 존재하는 A 테이블의 데이터를 추출
1
2
3
4
5
6
7
8
9
10SELECT
department_id
, department_name
FROM departments a
WHERE EXISTS (SELECT *
FROM employees b
WHERE a.department_id = b.department_id
AND b.salary > 3000
) --- EXISTS
ORDER BY a.department_name;IN
- 서브 쿼리 내에 두 테이블의 조인 조건이 없다
- IN 연산자는 OR 조건을 반환 가능
1
2
3
4
5
6
7
8
9SELECT
department_id
, department_name
FROM departments a
WHERE a.department_id IN (SELECT
b.department_id
FROM employees b
WHERE b.salary > 3000)
ORDER BY a.department_name;외부조인
- (+) 기호를 붙이는 형식
- 조인 조건에 만족하지 않더라도 데이터를 모두 추출함 (없으면 null값으로 출력)
1 | SELECT |
- 외부조인 시 조인 조건 모두에 (+)를 붙여야 함
1 | SELECT |
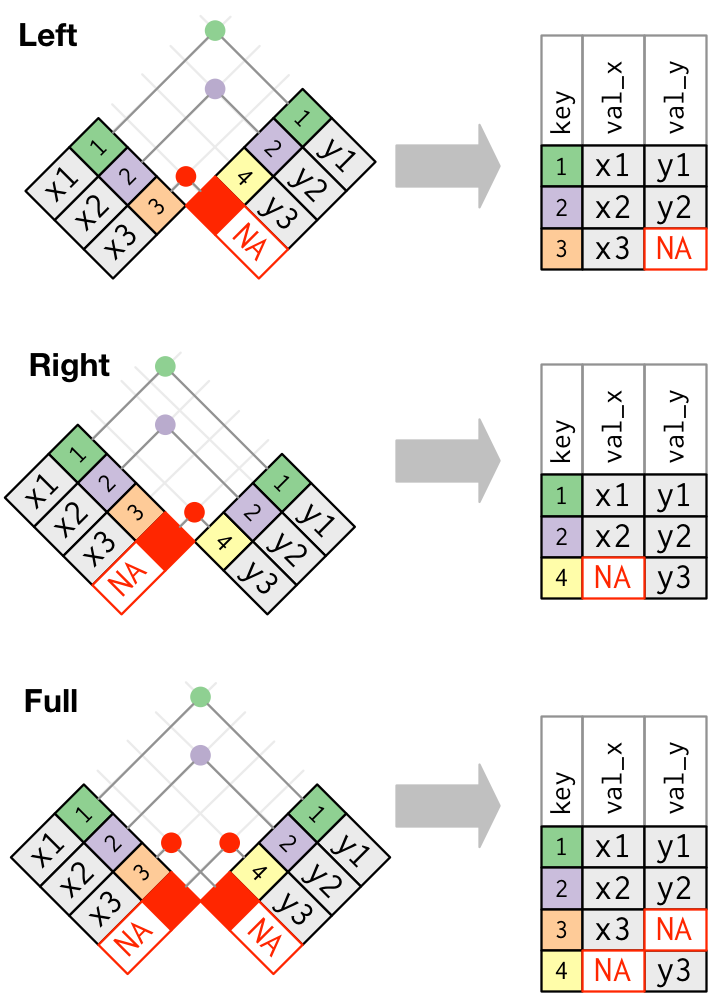
- 카타시안 조인
- WHERE절에 조인 조건이 없는 조인 방식
- FROM절에 2개 이상 테이블을 명시했으므로 일종의 조인 조건
1 | SELECT |
ANSI 조인
- 조인 조건이 WHERE 절이 아닌 FROM 절에 들어간다는 점이 기존 문법과 다름
- FROM 절에서 INNER JOIN 구문을 사용하며, 조인 조건은 ON 절에 , 조인 조건 외의 조건은 기존대로 WHERE 절에 명시
1 | SELECT |
서브쿼리
연관성 없는 서브 쿼리
- 메인 쿼리와의 연관성이 없는 서브쿼리를 말한다
- 메인 테이블과 조인 조건이 걸리지 않는 서브쿼리
- 메인 쿼리: 모든 사원 테이블을 조회하라 / 서브 : 사원 테이블의 평균 급여보다 많은 사원
1
2
3SELECT *
FROM employees
WHERE salary >= (SELECT AVG(salary) FROM employees);- parent_id 가 null인 부서번호를 가진 총 사원의 건수
1
2
3
4
5SELECT count(*)
FROM employees
WHERE department_id IN (SELECT department_id
FROM departments
WHERE parent_id IS NULL);연관성이 있는 서브 쿼리
- 메인쿼리와의 연관성이 있는 서브 쿼리
- 메인 테이블과 조인 조건이 걸린 서브 쿼리
- 메인: 부서 번호를 조회하라 / 서브 : 부서테이블의 부서번호와 job_history 테이블의 부서 번호가 같은 경우를 조회하라
1
2
3
4
5
6
7SELECT
a.department_id
, a.department_name
FROM departments a
WHERE EXISTS(SELECT 1
FROM job_history b
WHERE a.department_id = b.department_id);두 개의 서브쿼리(중첩 쿼리) 사용
연관성 없는 서브쿼리 :평균 급여를 구하고 이 값보다 큰 급여의 사원을 조회
연관성 있는 서브쿼리: 평균급여 이상을 받는 사원이 속한 부서를 추출
1
2
3
4
5
6
7
8SELECT a.department_id, a.department_name
FROM departments a
WHERE EXISTS (SELECT 1
FROM employees b
WHERE a.department_id = b.department_id
AND b.salary > (SELECT AVG(salary)
FROM employees)
);인라인 뷰
FROM절에 사용하는 서브 쿼리
2000년 이탈리아 평균 매출액(연평균)보다 큰 월의 평균 매출액 구하기
- 서브 1 : 월별 평균 매출액 구하는 것
- 서브 2 : 연평균 매출액을 구하는 것
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17SELECT a.*
FROM (SELECT a.sales_month, ROUND(AVG(a.amount_sold)) AS month_avg
FROM sales a, customers b, countries c
WHERE a.sales_month BETWEEN '200001' AND '200012'
AND a.cust_id = b.CUST_ID
AND b.COUNTRY_ID = c.COUNTRY_ID
AND c.COUNTRY_NAME = 'Italy'
GROUP BY a.sales_month) a
, (SELECT ROUND(AVG(a.amount_sold)) AS year_avg
FROM sales a
, customers b
, countries c
WHERE a.sales_month BETWEEN '20001' AND '200012'
AND a.cust_id = b.CUST_ID
AND b.COUNTRY_ID = c.COUNTRY_ID
AND c.COUNTRY_NAME = 'Italy' ) b
WHERE a.month_avg > b.year_avg;
ERD를 통해 도식화해서 보는 것을 추천
- ERD : 데이터베이스 구조를 한 눈에 알아보기 위해
고급 쿼리
- 복잡한 연산 결과를 추출해 내는 쿼리
- 작성법
- (1),(2) 메인쿼리 작성
- (3),(4) 서브쿼리 작성 후 합치기
- 이탈리아 매출액 데이터에서 연도별 매출 실적이 가장 많은 사원의 목록과 최대 매출액
- 이탈리아 고객 찾기 —> customers, countries country_id로 조인
- 이탈리아 매출액 찾기 —> 위의 결과와 sales 테이블을 cust_id 로 조인
- 최대 매출액은 MAX, 연도별은 GROUP BY로
1
2
3
4
5
6
7
8
9
10
11
12
13# (1)
SELECT
SUBSTR(a.sales_month, 1, 4) as years
, a.employee_id
, SUM(a.amount_sold) AS amount_sold
FROM
sales a
, customers b
, countries c
WHERE a.cust_id = b.cust_id
AND b.country_id = c.country_id
AND c.country_name = 'Italy'
GROUP BY SUBSTR(a.sales_month, 1, 4), a.employee_id;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19# (2)
SELECT
years
, MAX(amount_sold) AS max_sold
, MIN(amount_sold) AS min_sold
FROM (SELECT
SUBSTR(a.sales_month, 1, 4) as years
, a.employee_id
, SUM(a.amount_sold) AS amount_sold
FROM
sales a
, customers b
, countries c
WHERE a.cust_id = b.cust_id
AND b.country_id = c.country_id
AND c.country_name = 'Italy'
GROUP BY SUBSTR(a.sales_month, 1, 4), a.employee_id) K
GROUP BY years
ORDER BY years;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41# (1) + (2)
SELECT
emp.years
, emp.employee_id
, emp2.emp_name
, emp.amount_sold
FROM
(SELECT
SUBSTR(a.sales_month, 1, 4) as years
, a.employee_id
, SUM(a.amount_sold) AS amount_sold
FROM
sales a
, customers b
, countries c
WHERE a.cust_id = b.cust_id
AND b.country_id = c.country_id
AND c.country_name = 'Italy'
GROUP BY SUBSTR(a.sales_month, 1, 4), a.employee_id) emp
, (SELECT
years
, MAX(amount_sold) AS max_sold
, MIN(amount_sold) AS min_sold
FROM (SELECT
SUBSTR(a.sales_month, 1, 4) as years
, a.employee_id
, SUM(a.amount_sold) AS amount_sold
FROM
sales a
, customers b
, countries c
WHERE a.cust_id = b.cust_id
AND b.country_id = c.country_id
AND c.country_name = 'Italy'
GROUP BY SUBSTR(a.sales_month, 1, 4), a.employee_id) K
GROUP BY years) sale
, employees emp2
WHERE emp.years = sale.years
AND emp.amount_sold = sale.max_sold
AND emp.employee_id = emp2.employee_id
ORDER BY years;
분석함수
그룹 별 집계를 담당
종류
- WINDOW 절 : 파티션으로 분할된 그룹에 대해서 더 상세한 그룹으로 분할할 때 사용
- ORDER BY 절 : 파티션 안에서의 순서를 지정
- PARTITION BY 절 : 분석함수로 계산될 대상 로우의 그룹을 지정
ROW_NUMBER()
- 파티션으로 분할된 그룹별 각 로우에 대한 순번을 반환하는 함수
- 사원 테이블에서 부서별 사원들의 로우 수 출력
1
2
3
4
5
6SELECT
department_id
, emp_name
, ROW_NUMBER() OVER (PARTITION BY department_id
ORDER BY emp_name) dep_rows
FROM employees;RANK(), DENSE_RANK()
- 파티션별 순위 반환
- 부서별로 급여 순위 매기기
1
2
3
4
5
6
7
8
9SELECT
department_id
, emp_name
, salary
, RANK() OVER (PARTITION BY department_id
ORDER BY salary) dep_rank
, DENSE_RANK() OVER (PARTITION BY department_id
ORDER BY salary) dep_denserank
FROM employees;CUME_DIST & PERCENT_RANK
- CUME_DIST : 주어진 그룹에대한 상대 누적 분포도값 반환
1
2
3
4
5
6SELECT
department_id
, emp_name
, CUME_DIST() over (PARTITION BY department_id
ORDER BY salary) dep_dist
FROM employees;NTILE 함수
- NTILE(4) 값을 4등분 함
1
2
3
4
5
6
7
8SELECT
department_id
, emp_name
, salary
, NTILE(5) OVER (PARTITION BY department_id
ORDER BY salary) NTITLES
FROM employees
WHERE department_id IN (30,60);LAG 함수 & LEAD 함수
- LAG : 선행 로우의 값 참조
- LEAD : 후행 로우의 값 참조
1
2
3
4
5
6
7
8SELECT
emp_name
, hire_date
, salary
, LAG(salary, 1, 0) OVER (ORDER BY hire_date) AS prev_sal
, LEAD(salary, 1, 0) OVER (ORDER BY hire_date) AS next_sal
FROM employees
WHERE department_id
계층형 쿼리
- 계층형 구조 : 상하 수직 관계의 구조로 사원-대리-과장-부장/ 판매부-영업부 같은 구조가 속한다
- 또 다른 말로는 부모 컬럼, 자식 컬럼이라고도 표현한다
- 계층형 쿼리 구문
- START WITH 조건 : 최상위 계층의 로우를 식별, 즉 이 조건에 맞는 로우부터 계층형 구조를 풀어나간다는 의미
- CONNECT BY 조건 : 계층형 구조가 어떤식으로 연결되는지를 기술
부서 테이블은 parent_id 에 상위 부서 정보를 갖고 있음
→ ‘CONNECT BY PRIOR department_id (자식 컬럼) = parent_id (부모 컬럼)’CONNECT BY NOCYCLE 은 무한루프를 방지하기 위한 조건
1 | SELECT expr1, expr2,... |
WITH절
- 동일한 구문을 연결시켜줌
- WITH이 맨 앞에 오고 별칭을 앞에 명시한다는 점을 빼고는 일반 서브 쿼리와 비슷함
- 형식
1 | WITH 별칭1 AS (SELECT문), |

분석함수
- 특정 그룹별 집계를 해주므로 집계함수에 속함
- AVG
WINDOW 함수
- 파티션으로 분할된 그룹에 대해 별도로 다시 그룹(=부분집합)을 만드는 역할을 함
- 구문 형식
- ROWS : 로우 단위로 WINDOW절을 지정
- RANGE : 로우가 아닌 논리적인 범위로 WINDOW 절을 지정
- BETWEEN ~ AND : WINDOW 절의 시작과 끝 지점을 명시
- UNBOUNDED PRECEDING : 파티션으로 구분된 첫번째 로우를 시작 지점
- UNBOUNDED FOLLOWING : 파티션으로 구분된 마지막 로우를 끝 지점
- CURRENT ROW : 시작 및 끝 지점이 현재 로우가 됨
- value_expr PRECEDING : 끝 지점일 경우, 시작 지점은 value_expr PRECEDING
- value_expr FOLLOWING : 시작 지점일 경우, 끝 지점은 value_expr FOLLOWING
📌 SQL 책 추천 : 데이터 분석을 위한 SQL 레시피 (한빛 미디어, 가사키 나가토)
install_url to use ShareThis. Please set it in _config.yml.