Posted Updated Oh seungeun crawling6 minutes read (About 834 words) crawling basic
크롤링 기초
Python
웹상에 있는 데이터를 수집하는 도구
- BeautifulSoup 가장 일반적인 수집 도구 (CSS 통해서 수집)
- Scrapy (CSS, XPATH)
- Selenium (CSS, XPATH 통해서 데이터 수집 + JavaScript)
—> 자바 필요 + 몇개의 설치 도구 필요
웹사이트 만드는 3대 조건+1
- HTML, CSS, JavaScript, Ajax (비동기처리)
웹사이트 구동 방식
참고
- 네이버 같은 사이트에서 마우스 우클릭 → 검사로 가면 그 페이지의 html 형태? 를 볼 수 있다
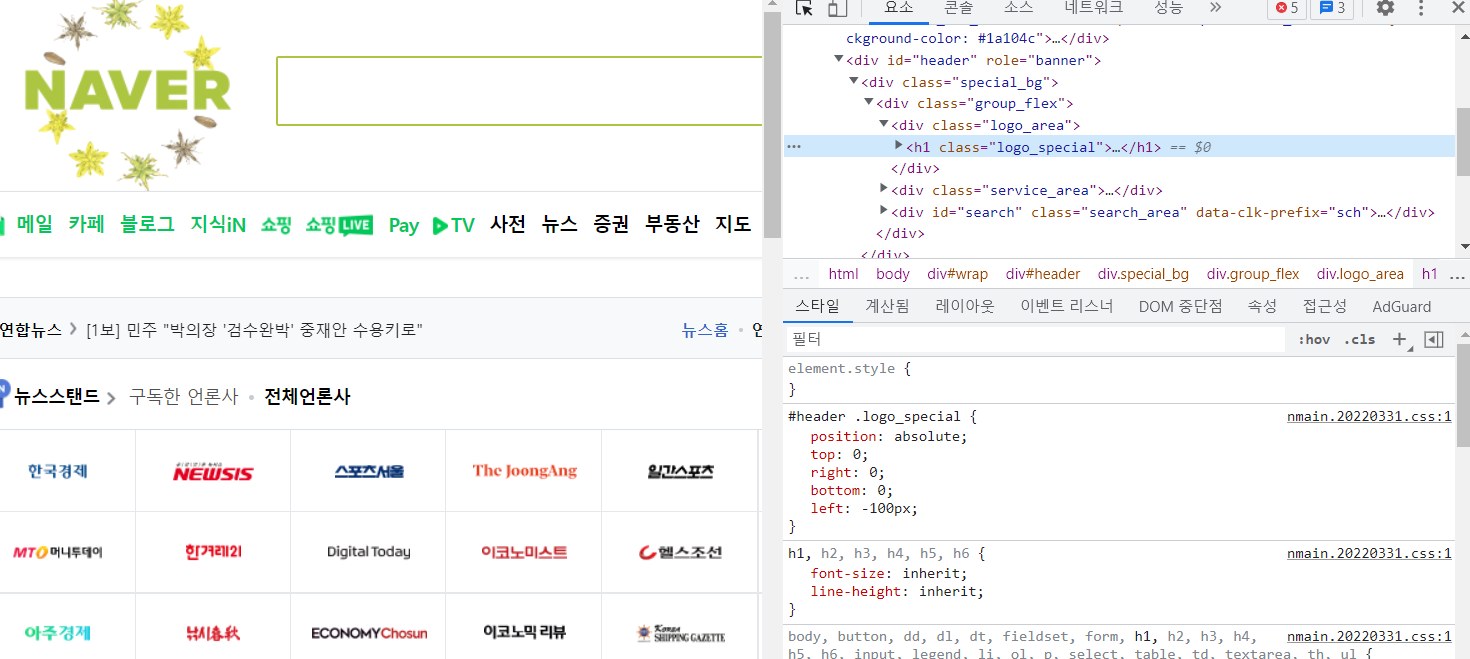
파이참으로 실습
- crawling 프로젝트 파일 생성
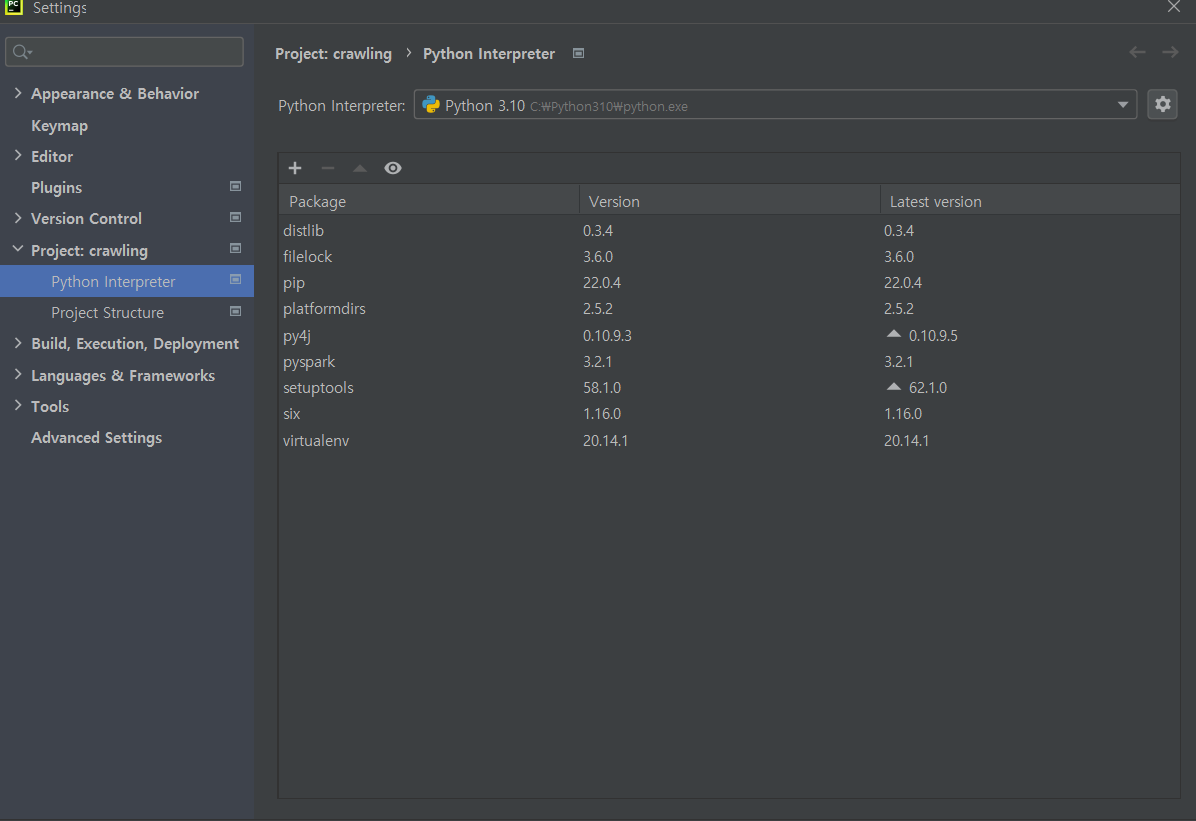
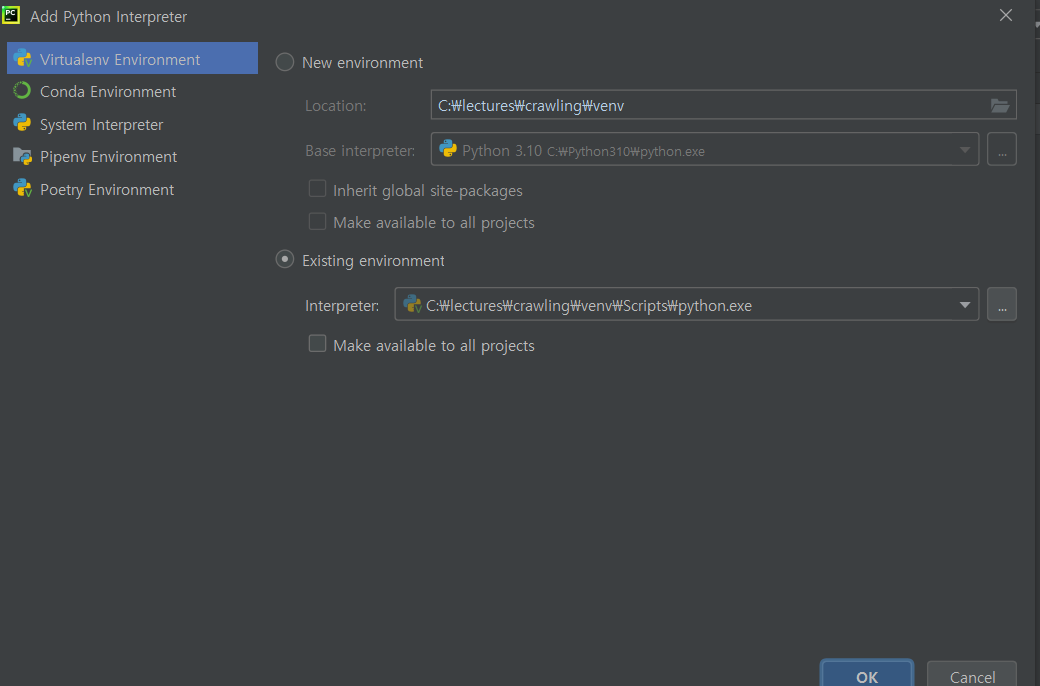
- (가상환경 세팅) 상단 탭 File → Settings → Project: crawling → Python Interpreter → 세팅 아이콘 클릭 → add 클릭 → new environment 클릭
- 터미널에서 가상환경 세팅(source venv/Scripts/activate 명령어 입력) 후 필요한 라이브러리들 설치 (pandas, numpy, beautifulsoup4, requests 등등)
- html 파일을 만든다 (crawling 우클릭→ new → html) 파일명은 임의로 index로 설정
- html의 기본 구조 ( ,)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| <!DOCTYPE html>
<html lang="en">
<head>
<meta charset="="UTF-8">
<titl> CRAWLING TEST </titl>
</head>
<body>
<h1>aaaaaaa</h1>
<h2>bbbbbbbb</h2>
<div class="chapter01">
<p> DON'T CRAWL HERE </p>
</div>
<div class="chapter02">
<p> JUST CRAWLING HERE </p>
</div>
<div id = "main">
<p> crawling</p>
</div>
</body>
</html>
|
뉴스 헤드라인 크롤링
- 네이버 → 우클릭 : 검사 → 네트워크 → 문서 → 헤더에서 요청메서드가 get 방식인지 확인
- 라이브러리( 기본 : bs4, requests) 임포트 한다
- referer에는 사이트 검사에서 찾은 referer 복사, user-agent 도 복붙
- req. status_code를 했을 때 200이 나오면 정상, 404 주소오류, 503은 서버가 내려진 상태
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| def main():
CUSTOM_HEADER= {
'referer':'https://www.naver.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36'
}
url = 'https://www.naver.com/'
req = requests.get(url = url, headers=CUSTOM_HEADER)
print(req.status_code)
print(req.text)
# print("크롤링 완성!")
if __name__ == "__main__":
main()
|
벅스 차트 크롤링
- 검사 → 네트워크 → 닥스 → 헤더에서 referer확인 및 user-agent 확인 (* referer는 항상 있는게 아니라 없을 때도 있음, 그럼 안 쓰면 된다)
- url 에는 request URL(요청 URL) 을 넣는다
- 상태코드로 웹사이트 들어갔는지 확인
- BeautifulSoup으로 실행
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| import requests
from bs4 import BeautifulSoup
import pandas as pd
def main():
CUSTOM_HEADER = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36'
}
url = 'https://music.bugs.co.kr/chart'
req = requests.get(url = url, headers=CUSTOM_HEADER)
if req.status_code == 200:
print("상태코드 : ", req.status_code)
print("실행")
soup = BeautifulSoup(req.text, 'html.parser')
crawling(soup)
else:
print("웹사이트 확인하세요", url)
# soup = BeautifulSoup(req.text, 'html.parser')
# crawling(soup)
if __name__ == "__main__":
main()
|
- 사용자 정의 함수 crawling으로 가서 차트가 어디 태그에 속해있는지 확인 (차트의 최상위 태그는 tbody, class는 없으므로 생략한다)
- 타이틀은 p태그 안에 있으므로 반복문으로 뽑는다
- p태그는 타이틀말고도 다른 텍스트에도 달려있으므로 클래스를 타이틀로 지정하여 타이틀만 뽑도록한다
- p.get_text()로 잘 나왔는지 출력해본다
- ‘\n’ 문자열까지 나왔으므로 이를 제거하고 출력해준다 (* strip(’\n’))
- 배열로 변환된 결과를 출력한다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| def crawling(soup):
print("크롤링 완성!")
tbody_df = soup.find("tbody")
# print(tbody_df)
result = []
for p in tbody_df.find_all("p", class_="title"):
print(p.get_text().strip('\n'))
# (1)
result.append(p.get_text().strip('\n'))
# result.append(p.get_text().replace("\n", ""))
# (2)
print(result)
|
You need to set install_url to use ShareThis. Please set it in _config.yml.