crawling basic
크롤링 기초
Python
웹상에 있는 데이터를 수집하는 도구
- BeautifulSoup 가장 일반적인 수집 도구 (CSS 통해서 수집)
- Scrapy (CSS, XPATH)
- Selenium (CSS, XPATH 통해서 데이터 수집 + JavaScript)
—> 자바 필요 + 몇개의 설치 도구 필요
웹사이트 만드는 3대 조건+1
- HTML, CSS, JavaScript, Ajax (비동기처리)
웹사이트 구동 방식
- GET / POST
참고
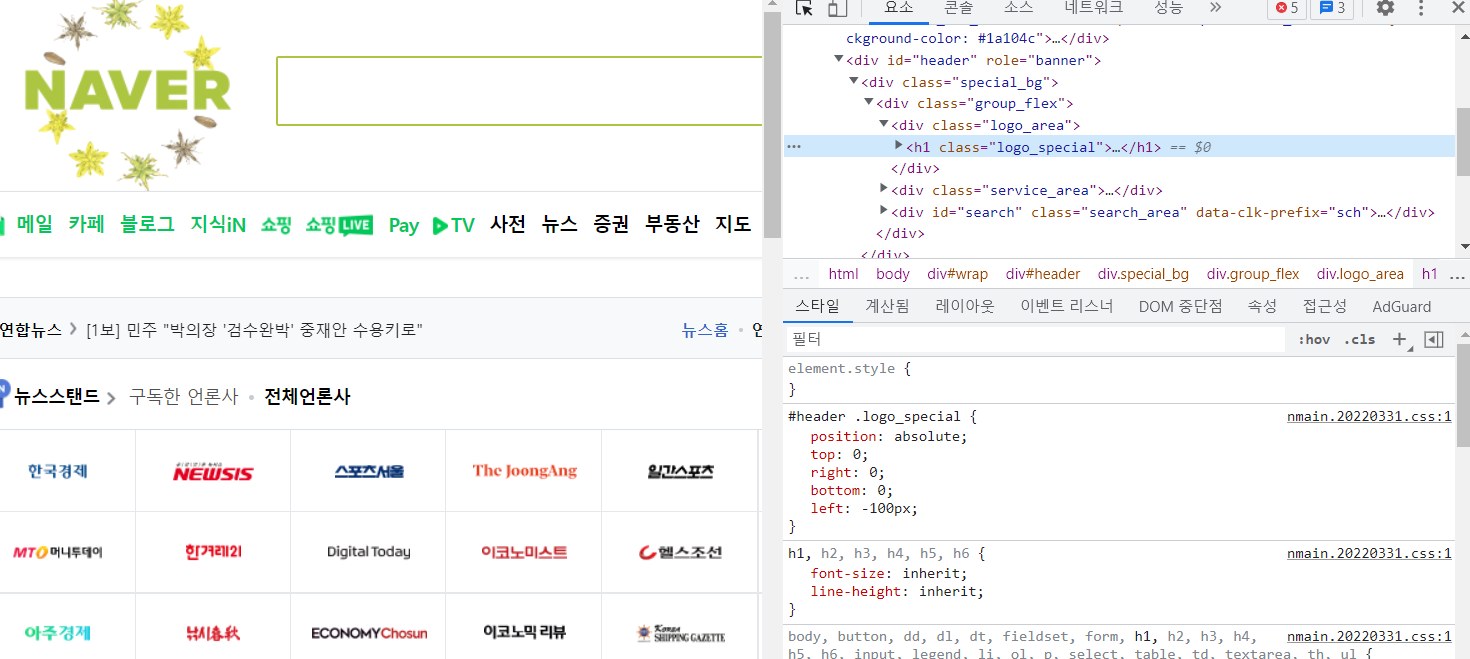
- 네이버 같은 사이트에서 마우스 우클릭 → 검사로 가면 그 페이지의 html 형태? 를 볼 수 있다
파이참으로 실습
- crawling 프로젝트 파일 생성
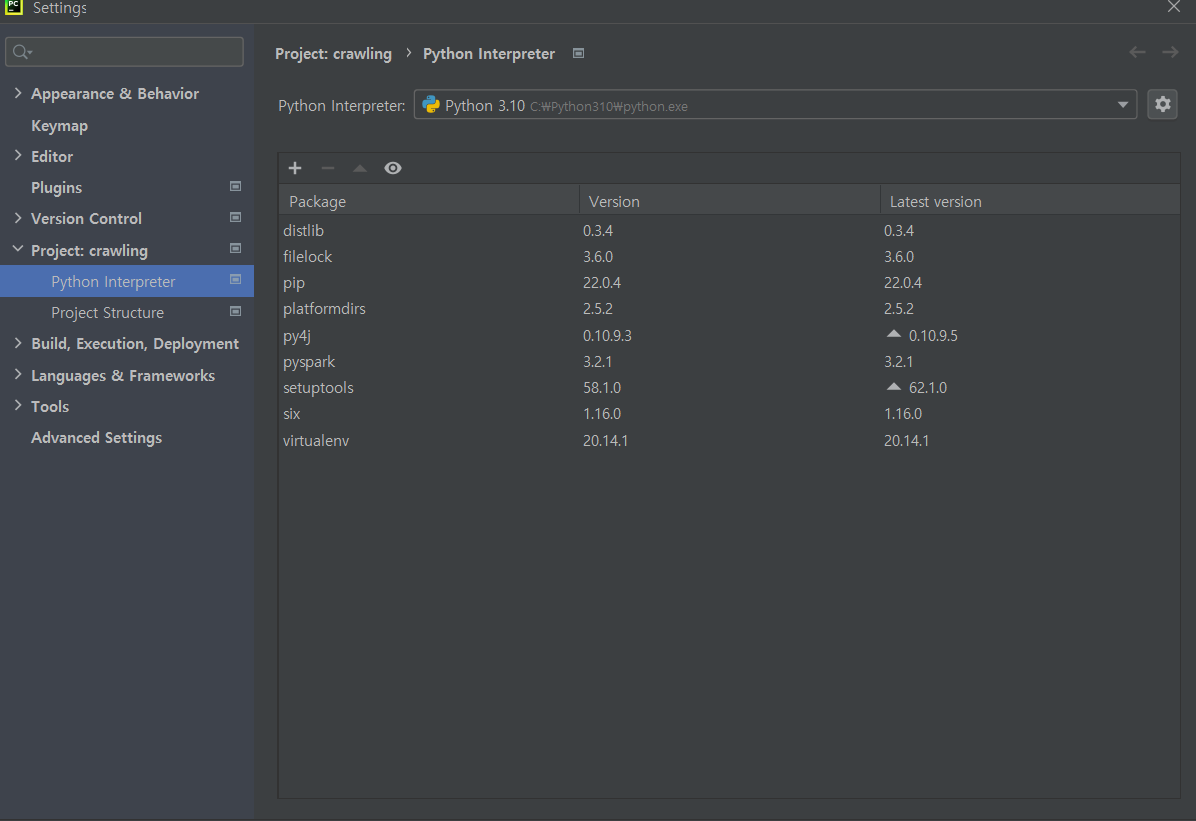
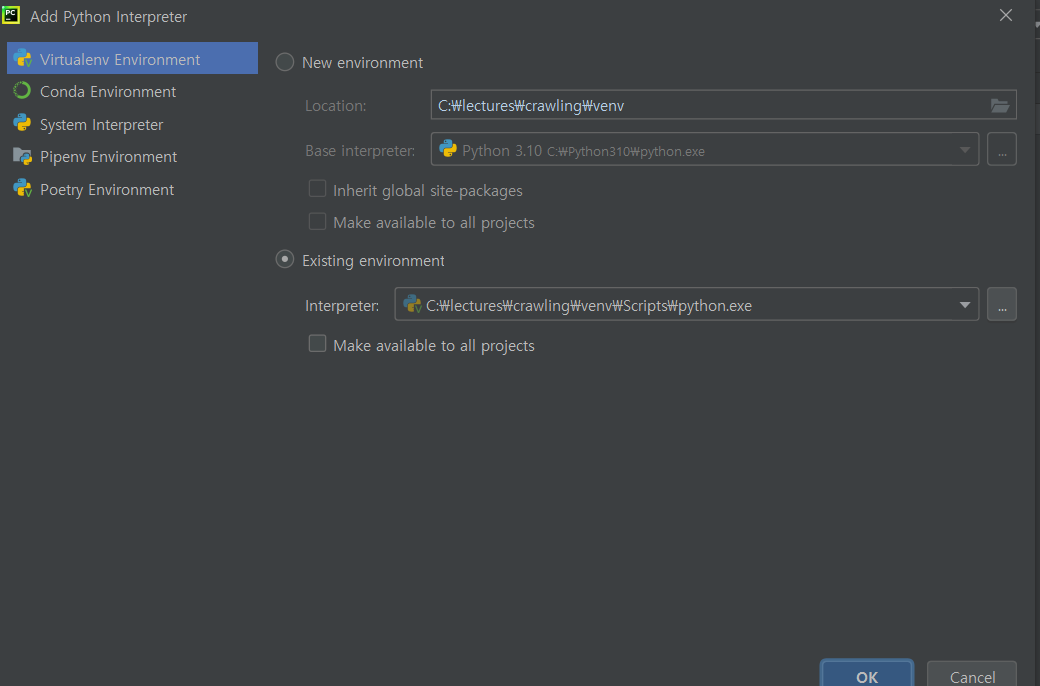
- (가상환경 세팅) 상단 탭 File → Settings → Project: crawling → Python Interpreter → 세팅 아이콘 클릭 → add 클릭 → new environment 클릭
- 터미널에서 가상환경 세팅(source venv/Scripts/activate 명령어 입력) 후 필요한 라이브러리들 설치 (pandas, numpy, beautifulsoup4, requests 등등)
- html 파일을 만든다 (crawling 우클릭→ new → html) 파일명은 임의로 index로 설정
- html의 기본 구조 ( ,)
1 | <!DOCTYPE html> |
뉴스 헤드라인 크롤링
- 네이버 → 우클릭 : 검사 → 네트워크 → 문서 → 헤더에서 요청메서드가 get 방식인지 확인
- 라이브러리( 기본 : bs4, requests) 임포트 한다
- referer에는 사이트 검사에서 찾은 referer 복사, user-agent 도 복붙
- req. status_code를 했을 때 200이 나오면 정상, 404 주소오류, 503은 서버가 내려진 상태
1 | def main(): |
벅스 차트 크롤링
- 검사 → 네트워크 → 닥스 → 헤더에서 referer확인 및 user-agent 확인 (* referer는 항상 있는게 아니라 없을 때도 있음, 그럼 안 쓰면 된다)
- url 에는 request URL(요청 URL) 을 넣는다
- 상태코드로 웹사이트 들어갔는지 확인
- BeautifulSoup으로 실행
1 | import requests |
- 사용자 정의 함수 crawling으로 가서 차트가 어디 태그에 속해있는지 확인 (차트의 최상위 태그는 tbody, class는 없으므로 생략한다)
- 타이틀은 p태그 안에 있으므로 반복문으로 뽑는다
- p태그는 타이틀말고도 다른 텍스트에도 달려있으므로 클래스를 타이틀로 지정하여 타이틀만 뽑도록한다
- p.get_text()로 잘 나왔는지 출력해본다
- ‘\n’ 문자열까지 나왔으므로 이를 제거하고 출력해준다 (* strip(’\n’))
- 배열로 변환된 결과를 출력한다
1 | def crawling(soup): |